Jeden z najważniejszych elementów pozycjonowania procesora Intel wśród władców jest technologia? Hyper Threading... A raczej jego brak w procesorze lub jego obecność. Za co odpowiada ta technologia? Intel Hyper-Threading, jest to technologia wydajnego wykorzystania zasobów rdzeni procesora (CPU), umożliwiająca jednoczesne przetwarzanie wielu wątków na rdzeń.
Spróbujmy podać przykład podobnego systemu z życia. Wyobraź sobie posterunek graniczny z kontrolą każdego samochodu, wielu celników i jeden pas dla samochodów. Powstaje korek, proces sam się zwalnia, nawet niezależnie od tempa pracy pracowników. A biorąc pod uwagę, że jest tylko jeden pas, połowa pracowników po prostu się nudzi. A potem nagle otwiera się kolejny pas dla pojazdów i samochody zaczynają podjeżdżać dwoma strumieniami. Szybkość pracy rośnie, wolni pracownicy zaczynają pracować, a korki osób chcących przekroczyć granicę stają się znacznie mniejsze. W efekcie, bez zwiększania wielkości urzędu celnego i liczby pracowników, wzrosła przepustowość i wydajność jednego punktu kontrolnego.
Nawet najpotężniejszy rdzeń procesora musi bezzwłocznie otrzymywać informacje, aby móc je szybko przetworzyć. Gdy tylko „wtyczka” danych zostanie utworzona na wejściu, procesor zaczyna stać bezczynnie, czekając na przetworzenie tej lub innej informacji.
Aby tego uniknąć, technologia pojawiła się już w 2002 roku Hyper Threading, który imitował pojawienie się drugiego rdzenia w systemie, dzięki czemu wypełnianie pojemności rdzenia było szybsze.
Jak pokazała praktyka, niewiele osób wie, jak faktycznie działa ta technologia. Intel Hyper-Threading... Większość z nich jest pewna, że ma tylko kilka dodatkowych wirtualnych rdzeni w swoim procesorze. Ale w rzeczywistości liczba rdzeni się nie zmienia, zmienia się liczba wątków, a to jest niezwykle ważne. Tyle, że każdy rdzeń ma dodatkowy kanał wejścia-wyjścia informacji. Poniżej znajduje się film pokazujący, jak to faktycznie działa.
Jak działa technologia HT i skąd pochodzą dodatkowe strumienie? W rzeczywistości wszystko jest dość proste. Aby wdrożyć tę technologię, do każdego rdzenia dodawany jest jeden kontroler i zestaw rejestrów. Tak więc, gdy tylko przepływ danych przekroczy szerokość pasma jednego kanału, drugi kanał jest podłączony. W ten sposób wyeliminowane są bezczynne bloki procesora.

W dobie procesorów jednordzeniowych (Intel Pentium 4) technologia HT stała się wybawieniem dla tych, którzy nie mogli kupić droższego procesora (Pentium D). Ale dzisiaj znane są przypadki pogorszenia wydajności po aktywacji HT. Dlaczego to się dzieje? To całkiem proste. W celu zrównoleglania danych i prawidłowego przetwarzania procesu zużywana jest również część mocy procesora. A gdy tylko pojawi się wystarczająca liczba fizycznych rdzeni, aby przetwarzać informacje bez bezczynnych bloków, wydajność nieznacznie spada ze względu na zasoby wybrane przez technologię HT. Dlatego najgorszym przypadkiem dla Hyper-Threadingu nie jest brak wzrostu wydajności, ale jej spadek. Ale w praktyce zdarza się to bardzo rzadko.

Wraz z wydaniem ośmiotysięcznej linii procesorów Intel z rodziny Core pytanie to stało się szczególnie istotne - czy jest to konieczne Hyper Threading ogólnie? W końcu nawet procesory Core i5 mają pełne sześć rdzeni. Poza profesjonalnymi aplikacjami do przetwarzania grafiki, renderowania itp., wtedy jest szansa, że sześć fizycznych rdzeni wystarczy dla wszystkich aplikacji biurowych i gier. Dlatego jeśli początkowo uważano, że technologia HT zwiększa wydajność procesora o 30%, teraz nie jest to aksjomat i wszystko będzie zależeć od stylu pracy przy komputerze i zestawu używanych narzędzi.
Oczywiście tekst byłby niekompletny bez testów. Dlatego weźmiemy procesory, które posiadamy. Intel Core i7 8700K oraz 7700K i sprawdź w kilku grach i aplikacjach wydajność procesorów z aktywowanym Hyper Threading i dezaktywowany. W wyniku testów stanie się jasne, w których aplikacjach wirtualne rdzenie zwiększają wydajność, a w których pozostają niezauważone.

Popularny 3DMark niechętnie reaguje na wzrost liczby rdzeni i wątków. Jest wzrost, ale jest on znikomy.

W różnego rodzaju obliczeniach i przetwarzaniu zawsze rządziły jądra i wątki. Hyper-Threading jest tutaj niezbędny, znacznie zwiększa wydajność.

W grach sytuacja jest prostsza. W większości przypadków zwiększanie liczby wątków jest nieskuteczne, tj. Do gier wystarczą 4 rdzenie fizyczne, a w większości przypadków nawet mniej. Jedynym wyjątkiem był GTA5, który bardzo dobrze zareagował na wyłączenie NT i dodał 7% wydajności, i to tylko na sześciordzeniowym procesorze 8700K. Wyłączenie wielowątkowości przy 7700K nie dało żadnych rezultatów. Kilkakrotnie przekroczyliśmy benchmarki i wyniki pozostały bez zmian. Ale to raczej wyjątek od reguły. Wszystkie testowane gry są z łatwością zadowolone z czterech rdzeni.
Jednym z najważniejszych elementów w pozycjonowaniu procesorów Intela w liniach jest technologia Hyper-Threading. A raczej jego brak w procesorze lub jego obecność. Za co odpowiada ta technologia? Intel Hyper-Threading to technologia wydajnego wykorzystania zasobów rdzenia procesora (CPU), umożliwiająca jednoczesne przetwarzanie wielu wątków na rdzeń. Spróbujmy podać przykład podobnego systemu z życia. Wyobraź sobie posterunek graniczny z kontrolą każdego samochodu, wielu celników i jeden pas dla samochodów. Powstaje korek, proces sam się zwalnia, nawet niezależnie od tempa pracy pracowników. A biorąc pod uwagę, że jest tylko jeden pas, połowa pracowników po prostu się nudzi. A potem nagle otwiera się kolejny pas dla pojazdów i samochody zaczynają podjeżdżać dwoma strumieniami. Szybkość pracy rośnie, wolni pracownicy zaczynają pracować, a korki osób chcących przekroczyć granicę stają się znacznie mniejsze. W efekcie, bez zwiększania wielkości urzędu celnego i liczby pracowników, wzrosła przepustowość i wydajność jednego punktu kontrolnego. Nawet najpotężniejszy rdzeń procesora musi bezzwłocznie otrzymywać informacje, aby móc je szybko przetworzyć. Gdy tylko „wtyczka” danych zostanie utworzona na wejściu, procesor zaczyna stać bezczynnie, czekając na przetworzenie tej lub innej informacji. Aby temu zapobiec, już w 2002 roku pojawiła się technologia Hyper-Threading, która imitowała pojawienie się w systemie drugiego rdzenia, dzięki czemu wypełnianie pojemności rdzenia było szybsze. Jak pokazuje praktyka, niewiele osób wie, jak faktycznie działa technologia Intel Hyper-Threading. Większość z nich jest pewna, że ma tylko kilka dodatkowych wirtualnych rdzeni w swoim procesorze. Ale w rzeczywistości liczba rdzeni się nie zmienia, zmienia się liczba wątków, a to jest niezwykle ważne. Tyle, że każdy rdzeń ma dodatkowy kanał wejścia-wyjścia informacji. Poniżej znajduje się film pokazujący, jak to faktycznie działa. Jak działa technologia HT i skąd pochodzą dodatkowe strumienie? W rzeczywistości wszystko jest dość proste. Aby wdrożyć tę technologię, do każdego rdzenia dodawany jest jeden kontroler i zestaw rejestrów. Tak więc, gdy tylko przepływ danych przekroczy szerokość pasma jednego kanału, drugi kanał jest podłączony. W ten sposób wyeliminowane są bezczynne bloki procesora. W dobie procesorów jednordzeniowych (Intel Pentium 4) technologia HT stała się wybawieniem dla tych, którzy nie mogli kupić droższego procesora (Pentium D). Ale dzisiaj znane są przypadki pogorszenia wydajności po aktywacji HT. Dlaczego to się dzieje? To całkiem proste. W celu zrównoleglania danych i prawidłowego przetwarzania procesu zużywana jest również część mocy procesora. A gdy tylko pojawi się wystarczająca liczba fizycznych rdzeni, aby przetwarzać informacje bez bezczynnych bloków, wydajność nieznacznie spada ze względu na zasoby wybrane przez technologię HT. Dlatego najgorszym przypadkiem dla Hyper-Threadingu nie jest brak wzrostu wydajności, ale jej spadek. Ale w praktyce zdarza się to bardzo rzadko. Wraz z wprowadzeniem na rynek ośmiotysięcznej linii procesorów Intel Core pytanie to stało się szczególnie istotne - czy Hyper-Threading jest naprawdę konieczny? W końcu nawet procesory Core i5 mają pełne sześć rdzeni. Poza profesjonalnymi aplikacjami do przetwarzania grafiki, renderowania itp., wtedy jest szansa, że sześć fizycznych rdzeni wystarczy dla wszystkich aplikacji biurowych i gier. Dlatego jeśli początkowo uważano, że technologia HT zwiększa wydajność procesora o 30%, teraz nie jest to aksjomat i wszystko będzie zależeć od stylu pracy przy komputerze i zestawu używanych narzędzi. Oczywiście tekst byłby…
Był czas, kiedy trzeba było ocenić wydajność pamięci w kontekście technologii Hyper-threading. Doszliśmy do wniosku, że jego wpływ nie zawsze jest pozytywny. Gdy pojawił się kwant wolnego czasu, pojawiła się chęć kontynuowania badań i badania procesów zachodzących z dokładnością do cykli zegarowych maszyn i bitów, przy użyciu oprogramowania własnej konstrukcji.
Platforma badawcza
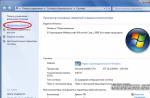
Obiektem eksperymentów jest laptop ASUS N750JK z procesorem Intel Core i7-4700HQ. Częstotliwość zegara 2,4 GHz, do 3,4 GHz z technologią Intel Turbo Boost. Zainstalowano 16 gigabajtów pamięci RAM DDR3-1600 (PC3-12800), działającej w trybie dwukanałowym. System operacyjny — Microsoft Windows 8.1 64 bity.Rys.1 Konfiguracja badanej platformy.
Procesor badanej platformy zawiera 4 rdzenie, które przy włączonej technologii Hyper-Threading zapewniają sprzętową obsługę 8 wątków lub procesorów logicznych. Oprogramowanie sprzętowe platformy przesyła te informacje do systemu operacyjnego za pośrednictwem tabeli ACPI Multiple APIC Description Table (MADT). Ponieważ platforma zawiera tylko jeden kontroler pamięci RAM, nie istnieje SRAT (tabela koligacji zasobów systemu), która deklaruje bliskość rdzeni procesora do kontrolerów pamięci. Oczywiście badany laptop nie jest platformą NUMA, ale system operacyjny, na potrzeby unifikacji, traktuje go jako system NUMA z jedną domeną, o czym świadczy linia NUMA Nodes = 1. Fakt, który jest dla nas fundamentalny eksperymenty polegają na tym, że pamięć podręczna danych pierwszego poziomu ma rozmiar 32 kilobajtów dla każdego z czterech rdzeni. Dwa procesory logiczne współdzielące jeden rdzeń współdzielą pamięci podręczne L1 i L2.
Badana operacja
Zbadamy zależność szybkości odczytu bloku danych od jego rozmiaru. W tym celu wybierzemy najbardziej wydajną metodę, a mianowicie odczyt 256-bitowych operandów za pomocą instrukcji VMOVAPD AVX. Na wykresach oś X to rozmiar bloku, oś Y to prędkość odczytu. W pobliżu punktu X, który odpowiada rozmiarowi pamięci podręcznej L1, spodziewamy się punktu przegięcia, ponieważ wydajność powinna spaść po tym, jak przetwarzany blok wyjdzie z pamięci podręcznej. W naszym teście, w przypadku przetwarzania wielowątkowego, każdy z 16 zainicjowanych wątków działa z osobnym zakresem adresów. Aby kontrolować technologię Hyper-Threading w aplikacji, każdy wątek używa funkcji API SetThreadAffinityMask, która ustawia maskę, w której jeden bit odpowiada każdemu procesorowi logicznemu. Pojedyncza wartość bitowa pozwala na użycie określonego procesora przez określony strumień, wartość zerowa wyłącza go. Dla 8 procesorów logicznych badanej platformy maska 11111111b pozwala na użycie wszystkich procesorów (Hyper-Threading jest włączone), maska 01010101b pozwala na użycie jednego procesora logicznego w każdym rdzeniu (Hyper-Threading jest wyłączone).Na wykresach zastosowano następujące skróty:
MBPS (megabajty na sekundę) – prędkość odczytu bloku w megabajtach na sekundę;
CPI (zegary na instrukcję) – liczba kleszczy na instrukcję;
TSC (licznik znaczników czasu) – licznik cykli procesora.
Uwaga: Szybkość zegara rejestru TSC może nie odpowiadać szybkości zegara procesora podczas pracy w trybie Turbo Boost. Należy to wziąć pod uwagę podczas interpretacji wyników.
Po prawej stronie wykresów wizualizowany jest szesnastkowy zrzut instrukcji, które tworzą treść pętli operacji docelowej wykonywanej w każdym ze strumieni programu lub pierwsze 128 bajtów tego kodu.
Doświadczenie numer 1. Jeden strumień

Rys. 2 Czytanie w jednym strumieniu
Maksymalna prędkość to 213563 megabajtów na sekundę. Punkt przegięcia występuje przy wielkości bloku około 32 kilobajtów.
Doświadczenie numer 2. 16 wątków dla 4 procesorów, Hyper-Threading jest wyłączony

Rys. 3 Czytanie w szesnastu wątkach. Liczba używanych procesorów logicznych to cztery
Hyper-Threading jest wyłączony. Maksymalna prędkość to 797598 megabajtów na sekundę. Punkt przegięcia występuje przy wielkości bloku około 32 kilobajtów. Zgodnie z oczekiwaniami, w porównaniu do odczytu jednego wątku, prędkość wzrosła około 4 razy, jeśli chodzi o liczbę pracujących rdzeni.
Doświadczenie numer 3. 16 wątków dla 8 procesorów, włączona Hyper-Threading

Rys. 4 Czytanie w szesnastu wątkach. Liczba używanych procesorów logicznych to osiem
Hyper-Threading jest włączony. Maksymalna prędkość wynosi 800722 megabajtów na sekundę; w wyniku włączenia funkcji Hyper-Threading prawie nie wzrosła. Dużym minusem jest to, że punkt przegięcia występuje, gdy rozmiar bloku wynosi około 16 kilobajtów. Włączenie funkcji Hyper-Threading nieznacznie zwiększyło prędkość maksymalną, ale spadek prędkości występuje teraz, gdy rozmiar bloku jest o połowę mniejszy – około 16 kilobajtów, więc średnia prędkość znacznie spadła. Nie jest to zaskakujące, każdy rdzeń ma własną pamięć podręczną L1, podczas gdy procesory logiczne tego samego rdzenia ją współdzielą.
wnioski
Badana operacja dobrze skaluje się na procesorze wielordzeniowym. Powody - każdy z rdzeni zawiera własną pamięć cache pierwszego i drugiego poziomu, wielkość bloku docelowego jest porównywalna z wielkością pamięci cache, a każdy z wątków operuje własnym zakresem adresów. Dla celów akademickich stworzyliśmy takie warunki w teście syntetycznym, zdając sobie sprawę, że rzeczywiste aplikacje są zwykle dalekie od idealnej optymalizacji. Ale włączenie Hyper-Threadingu, nawet w tych warunkach, dało negatywny efekt, przy niewielkim wzroście prędkości szczytowej następuje znaczna utrata prędkości przetwarzania bloków, których wielkość waha się od 16 do 32 kilobajtów. 20 stycznia 2015 o 19:43Jeszcze raz o Hyper-Threading
- testowanie systemów informatycznych,
- Programowanie
Był czas, kiedy trzeba było ocenić wydajność pamięci w kontekście technologii Hyper-threading. Doszliśmy do wniosku, że jego wpływ nie zawsze jest pozytywny. Gdy pojawił się kwant wolnego czasu, pojawiła się chęć kontynuowania badań i badania procesów zachodzących z dokładnością do cykli zegarowych maszyn i bitów, przy użyciu oprogramowania własnej konstrukcji.
Platforma badawcza
Obiektem eksperymentów jest laptop ASUS N750JK z procesorem Intel Core i7-4700HQ. Częstotliwość zegara 2,4 GHz, do 3,4 GHz z technologią Intel Turbo Boost. Zainstalowano 16 gigabajtów pamięci RAM DDR3-1600 (PC3-12800), działającej w trybie dwukanałowym. System operacyjny — Microsoft Windows 8.1 64 bity.Rys.1 Konfiguracja badanej platformy.
Procesor badanej platformy zawiera 4 rdzenie, które przy włączonej technologii Hyper-Threading zapewniają sprzętową obsługę 8 wątków lub procesorów logicznych. Oprogramowanie sprzętowe platformy przesyła te informacje do systemu operacyjnego za pośrednictwem tabeli ACPI Multiple APIC Description Table (MADT). Ponieważ platforma zawiera tylko jeden kontroler pamięci RAM, nie istnieje SRAT (tabela koligacji zasobów systemu), która deklaruje bliskość rdzeni procesora do kontrolerów pamięci. Oczywiście badany laptop nie jest platformą NUMA, ale system operacyjny, na potrzeby unifikacji, traktuje go jako system NUMA z jedną domeną, o czym świadczy linia NUMA Nodes = 1. Fakt, który jest dla nas fundamentalny eksperymenty polegają na tym, że pamięć podręczna danych pierwszego poziomu ma rozmiar 32 kilobajtów dla każdego z czterech rdzeni. Dwa procesory logiczne współdzielące jeden rdzeń współdzielą pamięci podręczne L1 i L2.
Badana operacja
Zbadamy zależność szybkości odczytu bloku danych od jego rozmiaru. W tym celu wybierzemy najbardziej wydajną metodę, a mianowicie odczyt 256-bitowych operandów za pomocą instrukcji VMOVAPD AVX. Na wykresach oś X to rozmiar bloku, oś Y to prędkość odczytu. W pobliżu punktu X, który odpowiada rozmiarowi pamięci podręcznej L1, spodziewamy się punktu przegięcia, ponieważ wydajność powinna spaść po tym, jak przetwarzany blok wyjdzie z pamięci podręcznej. W naszym teście, w przypadku przetwarzania wielowątkowego, każdy z 16 zainicjowanych wątków działa z osobnym zakresem adresów. Aby kontrolować technologię Hyper-Threading w aplikacji, każdy wątek używa funkcji API SetThreadAffinityMask, która ustawia maskę, w której jeden bit odpowiada każdemu procesorowi logicznemu. Pojedyncza wartość bitowa pozwala na użycie określonego procesora przez określony strumień, wartość zerowa wyłącza go. Dla 8 procesorów logicznych badanej platformy maska 11111111b pozwala na użycie wszystkich procesorów (Hyper-Threading jest włączone), maska 01010101b pozwala na użycie jednego procesora logicznego w każdym rdzeniu (Hyper-Threading jest wyłączone).Na wykresach zastosowano następujące skróty:
MBPS (megabajty na sekundę) – prędkość odczytu bloku w megabajtach na sekundę;
CPI (zegary na instrukcję) – liczba kleszczy na instrukcję;
TSC (licznik znaczników czasu) – licznik cykli procesora.
Uwaga: Szybkość zegara rejestru TSC może nie odpowiadać szybkości zegara procesora podczas pracy w trybie Turbo Boost. Należy to wziąć pod uwagę podczas interpretacji wyników.
Po prawej stronie wykresów wizualizowany jest szesnastkowy zrzut instrukcji, które tworzą treść pętli operacji docelowej wykonywanej w każdym ze strumieni programu lub pierwsze 128 bajtów tego kodu.
Doświadczenie numer 1. Jeden strumień
Rys. 2 Czytanie w jednym strumieniu
Maksymalna prędkość to 213563 megabajtów na sekundę. Punkt przegięcia występuje przy wielkości bloku około 32 kilobajtów.
Doświadczenie numer 2. 16 wątków dla 4 procesorów, Hyper-Threading jest wyłączony
Rys. 3 Czytanie w szesnastu wątkach. Liczba używanych procesorów logicznych to cztery
Hyper-Threading jest wyłączony. Maksymalna prędkość to 797598 megabajtów na sekundę. Punkt przegięcia występuje przy wielkości bloku około 32 kilobajtów. Zgodnie z oczekiwaniami, w porównaniu do odczytu jednego wątku, prędkość wzrosła około 4 razy, jeśli chodzi o liczbę pracujących rdzeni.
Doświadczenie numer 3. 16 wątków dla 8 procesorów, włączona Hyper-Threading
Rys. 4 Czytanie w szesnastu wątkach. Liczba używanych procesorów logicznych to osiem
Hyper-Threading jest włączony. Maksymalna prędkość wynosi 800722 megabajtów na sekundę; w wyniku włączenia funkcji Hyper-Threading prawie nie wzrosła. Dużym minusem jest to, że punkt przegięcia występuje, gdy rozmiar bloku wynosi około 16 kilobajtów. Włączenie funkcji Hyper-Threading nieznacznie zwiększyło prędkość maksymalną, ale spadek prędkości występuje teraz, gdy rozmiar bloku jest o połowę mniejszy – około 16 kilobajtów, więc średnia prędkość znacznie spadła. Nie jest to zaskakujące, każdy rdzeń ma własną pamięć podręczną L1, podczas gdy procesory logiczne tego samego rdzenia ją współdzielą.
wnioski
Badana operacja dobrze skaluje się na procesorze wielordzeniowym. Powody - każdy z rdzeni zawiera własną pamięć cache pierwszego i drugiego poziomu, wielkość bloku docelowego jest porównywalna z wielkością pamięci cache, a każdy z wątków operuje własnym zakresem adresów. Dla celów akademickich stworzyliśmy takie warunki w teście syntetycznym, zdając sobie sprawę, że rzeczywiste aplikacje są zwykle dalekie od idealnej optymalizacji. Ale włączenie Hyper-Threadingu, nawet w tych warunkach, dało negatywny efekt, przy niewielkim wzroście prędkości szczytowej następuje znaczna utrata prędkości przetwarzania bloków, których wielkość waha się od 16 do 32 kilobajtów.Jeśli dokładnie przejrzałeś zawartość BIOS Setup, być może zauważyłeś tam opcję CPU Hyper Threading Technology. Być może zastanawiałeś się, czym jest Hyper Threading (Hyper Threading Technology, oficjalna nazwa to Hyper Threading Technology, HTT) i do czego służy ta opcja.
Hyper Threading to stosunkowo nowa technologia opracowana przez firmę Intel dla procesorów o architekturze Pentium. Jak pokazuje praktyka, zastosowanie technologii Hyper Threading pozwoliło w wielu przypadkach na zwiększenie wydajności procesora o około 20-30%.
Tutaj musisz pamiętać, jak ogólnie działa centralny procesor komputera. Gdy tylko włączysz komputer i uruchomisz na nim program, procesor zaczyna czytać zawarte w nim instrukcje, zapisane w tzw. kodzie maszynowym. Odczytuje po kolei każdą instrukcję i wykonuje je jedna po drugiej.
Jednak wiele programów ma jednocześnie kilka uruchomionych procesów oprogramowania. Ponadto nowoczesne systemy operacyjne pozwalają użytkownikowi na uruchomienie kilku programów jednocześnie. I nie tylko pozwalają - w rzeczywistości sytuacja, w której pojedynczy proces jest wykonywany w systemie operacyjnym, jest dziś absolutnie nie do pomyślenia. Dlatego procesory zaprojektowane według starych technologii miały niską wydajność w przypadkach, w których wymagane było przetwarzanie kilku jednoczesnych procesów jednocześnie.
Oczywiście w celu rozwiązania tego problemu można włączyć do systemu kilka procesorów na raz lub procesory wykorzystujące kilka fizycznych rdzeni obliczeniowych. Ale taka poprawa okazuje się kosztowna, trudna technicznie i nie zawsze skuteczna z praktycznego punktu widzenia.
Historia rozwoju
Dlatego zdecydowano się stworzyć taką technologię, która pozwoli na przetwarzanie kilku procesów na jednym rdzeniu fizycznym. W tym przypadku w przypadku programów sprawa będzie wyglądać tak, jakby w systemie było jednocześnie kilka rdzeni procesorów.
Obsługa technologii Hyper Threading pojawiła się po raz pierwszy w procesorach w 2002 roku. Były to procesory z rodziny Pentium 4 oraz procesory serwerowe Xeon o taktowaniu powyżej 2 GHz. Początkowo technologia nosiła nazwę kodową Jackson, ale potem jej nazwę zmieniono na Hyper Threading, co jest bardziej zrozumiałe dla ogółu społeczeństwa – co można z grubsza przetłumaczyć jako „super wątki”.
Jednocześnie, według Intela, powierzchnia matrycy procesora obsługującego Hyper Threading wzrosła w porównaniu z poprzednim modelem, który go nie obsługuje tylko o 5% przy wzroście wydajności średnio o 20%.
Pomimo tego, że technologia ogólnie działała dobrze, to z wielu powodów Intel Corporation zdecydował się wyłączyć technologię Hyper Threading w procesorach Core 2, które zastąpiły procesory Pentium 4. Hyper Threading jednak później pojawił się ponownie w Sandy Bridge, Ivy Bridge i Haswell, które zostały w nich znacznie przerobione.
Esencja technologii
Zrozumienie technologii Hyper Threading jest ważne, ponieważ jest to jedna z kluczowych funkcji procesorów Intel.
Pomimo wszystkich postępów, jakie poczyniły procesory, mają one jedną istotną wadę - mogą wykonywać tylko jedną instrukcję na raz. Załóżmy, że w tym samym czasie używasz aplikacji, takich jak edytor tekstu, przeglądarka i Skype. Z punktu widzenia użytkownika to środowisko programowe można nazwać wielozadaniowością, jednak z punktu widzenia procesora jest to dalekie od przypadku. Rdzeń procesora będzie nadal wykonywał jedną instrukcję przez określony czas. W takim przypadku zadanie procesora obejmuje podział zasobów czasowych procesora między poszczególne aplikacje. Ponieważ to sekwencyjne wykonywanie instrukcji jest niezwykle szybkie, nie zauważasz tego. I wydaje ci się, że nie ma opóźnienia.
Ale nadal jest opóźnienie. Opóźnienie wynika ze sposobu, w jaki procesor jest zasilany danymi dla każdego z programów. Każdy strumień danych musi dotrzeć w określonym czasie i zostać przetworzony przez procesor indywidualnie. Technologia Hyper Threading umożliwia każdemu rdzeniowi procesora planowanie przetwarzania danych i przydzielanie zasobów do dwóch wątków jednocześnie.

Należy zauważyć, że w rdzeniu nowoczesnych procesorów znajduje się jednocześnie kilka tak zwanych urządzeń wykonawczych, z których każde jest przeznaczone do wykonywania określonej operacji na danych. Jednocześnie niektóre z tych urządzeń wykonawczych mogą być bezczynne podczas przetwarzania danych jednego wątku.
Aby zrozumieć tę sytuację, możemy narysować analogię do pracowników pracujących w hali montażowej na przenośniku i przetwarzających różnego rodzaju części. Każdy pracownik wyposażony jest w określone narzędzie przeznaczone do wykonania określonego zadania. Jeśli jednak części dotrą w niewłaściwej kolejności, pojawiają się opóźnienia - ponieważ niektórzy pracownicy czekają na swoją kolej, aby rozpocząć pracę. Hyper Threading można porównać do dodatkowego przenośnika taśmowego, który został ułożony w sklepie, tak aby wcześniej bezczynni pracownicy mogli wykonywać swoje operacje niezależnie od innych. Wciąż jest jeden sklep, ale części są przetwarzane szybciej i wydajniej, dzięki czemu czas przestoju jest skrócony. W ten sposób Hyper Threading umożliwił użycie tych jednostek wykonawczych procesora, które były bezczynne podczas wykonywania instrukcji z pojedynczego wątku.
Gdy tylko włączysz komputer z dwurdzeniowym procesorem obsługującym Hyper Threading i otworzysz Menedżera zadań Windows z zakładki Wydajność, znajdziesz w nim cztery wykresy. Ale to nie znaczy, że faktycznie masz 4 rdzenie procesora.

Dzieje się tak, ponieważ system Windows zakłada, że każdy rdzeń ma dwa procesory logiczne. Termin „procesor logiczny” brzmi śmiesznie, ale oznacza procesor, który fizycznie nie istnieje. Windows może wysyłać strumienie danych do każdego procesora logicznego, ale w rzeczywistości pracę wykonuje tylko jeden rdzeń. Dlatego pojedynczy rdzeń z technologią Hyper Threading znacznie różni się od oddzielnych rdzeni fizycznych.
Technologia Hyper Threading wymaga wsparcia ze strony następującego sprzętu i oprogramowania:
- procesor
- Chipset płyty głównej
- System operacyjny
Zalety technologii
Zastanówmy się teraz nad kolejnym pytaniem – jak bardzo technologia Hyper Threading zwiększa wydajność komputera? W codziennych zadaniach, takich jak surfowanie po Internecie i pisanie, korzyści płynące z technologii nie są tak oczywiste. Należy jednak pamiętać, że dzisiejsze procesory są tak wydajne, że codzienne zadania rzadko obciążają procesor całkowicie. Poza tym wiele zależy również od tego, jak napisane jest oprogramowanie. Możesz mieć kilka programów działających jednocześnie, jednak patrząc na wykres obciążenia, zobaczysz, że tylko jeden procesor logiczny jest używany na rdzeń. Dzieje się tak, ponieważ oprogramowanie nie obsługuje dystrybucji procesów między rdzeniami.
Jednak w bardziej złożonych zadaniach Hyper Threading może być bardziej przydatny. Aplikacje, takie jak oprogramowanie do modelowania 3D, gry 3D, oprogramowanie do kodowania/dekodowania muzyki lub wideo, a także wiele aplikacji naukowych zostało napisanych, aby jak najlepiej wykorzystać wielowątkowość. Dlatego możesz skorzystać z wydajności komputera obsługującego technologię Hyper Threading, grając w zaawansowane gry, słuchając muzyki lub oglądając filmy. Wzrost wydajności może wynieść nawet 30%, chociaż mogą zdarzyć się sytuacje, w których Hyper Threading w ogóle nie zapewnia przewagi. Czasami w przypadku, gdy oba wątki ładują wszystkie jednostki wykonawcze procesora tymi samymi zadaniami, może wystąpić nawet niewielki spadek wydajności.
Wracając do obecności w konfiguracji BIOS odpowiedniej opcji, która pozwala ustawić parametry Hyper Threading, w większości przypadków zaleca się włączenie tej funkcji. Jednak zawsze możesz go wyłączyć, jeśli okaże się, że komputer działa z błędami lub nawet ma niższą wydajność niż oczekiwałeś.
Wniosek
Ponieważ maksymalny wzrost wydajności podczas korzystania z Hyper Threading wynosi 30%, nie można powiedzieć, że technologia jest równoznaczna z podwojeniem liczby rdzeni procesora. Niemniej jednak Hyper Threading jest przydatną opcją i jako właściciel komputera nie zaszkodzi. Jego zaleta jest szczególnie widoczna np. w takich przypadkach, gdy edytujesz pliki multimedialne lub używasz komputera jako stacji roboczej dla tak profesjonalnych programów jak Photoshop czy Maya.
Napisaliśmy, że stosowanie jednoprocesorowych systemów Xeon nie ma sensu, ponieważ przy wyższej cenie ich wydajność będzie taka sama jak Pentium 4 o tej samej częstotliwości. Teraz, po dokładniejszych badaniach, prawdopodobnie trzeba będzie wprowadzić do tego stwierdzenia małą poprawkę. Technologia Hyper-Threading zaimplementowana w Intel Xeon z rdzeniem Prestonia naprawdę działa i daje całkiem zauważalny efekt. Chociaż podczas korzystania z niego pojawia się wiele pytań ...
Daj wydajność
„Szybciej, jeszcze szybciej…”. Wyścig o wydajność trwa już od lat, a czasami nawet trudno powiedzieć, który element komputera przyspiesza. W tym celu wynajduje się coraz więcej nowych sposobów, a im dalej, w ten lawinowy proces inwestuje się bardziej wykwalifikowaną siłę roboczą i wysokiej jakości mózgi.
Z pewnością potrzebny jest stały wzrost wydajności. Przynajmniej jest to dochodowy biznes i zawsze będzie piękny sposób na zachęcenie użytkowników do uaktualnienia wczorajszego „superwydajnego procesora” do jutrzejszego „jeszcze bardziej super...” Na przykład jednoczesne rozpoznawanie mowy i symultaniczne tłumaczenie na inny język nie jest marzeniem każdego? Czy też niezwykle realistyczne gry o niemal „kinowej” jakości (całkowicie pochłaniające uwagę, a czasem prowadzące do poważnych zmian w psychice) – czy nie jest to aspiracją wielu graczy, młodych i starych?
Ale wyjmijmy w tym przypadku aspekty marketingowe z pudełka, skupiając się na technicznych. Co więcej, nie wszystko jest takie ponure: są zadania pilne (aplikacje serwerowe, obliczenia naukowe, modelowanie itp.), gdzie coraz większa wydajność, w szczególności procesorów centralnych, jest naprawdę potrzebna.
Jakie są więc sposoby na zwiększenie ich wydajności?
Podkręcanie... Możliwe jest dalsze „rozrzedzenie” procesu technologicznego i zwiększenie częstotliwości. Ale, jak wiesz, nie jest to łatwe i jest obarczone różnego rodzaju skutkami ubocznymi, takimi jak problemy z rozpraszaniem ciepła.
Zwiększanie zasobów procesora- na przykład zwiększenie rozmiaru pamięci podręcznej, dodanie nowych bloków (jednostek wykonawczych). Wszystko to pociąga za sobą wzrost liczby tranzystorów, wzrost złożoności procesora, zwiększenie powierzchni matrycy, a w konsekwencji kosztów.
Poza tym dwie poprzednie metody z reguły nie dają liniowego wzrostu wydajności. Jest to dobrze znane w przykładzie z Pentium 4: błędy w przewidywaniu rozgałęzień i przerwań powodują odrzucenie długiego potoku, co znacznie wpływa na ogólną wydajność.
Wieloprzetwarzanie... Instalowanie wielu procesorów i rozdzielanie pracy między nimi jest często dość wydajne. Ale to podejście nie jest bardzo tanie - każdy dodatkowy procesor zwiększa koszt systemu, a podwójna płyta główna jest znacznie droższa niż zwykła (nie wspominając o płytach głównych z obsługą czterech lub więcej procesorów). Ponadto nie wszystkie aplikacje korzystają z wydajności wieloprocesorowej na tyle, aby uzasadnić koszty.
Oprócz „czystego” przetwarzania wieloprocesowego istnieje kilka „pośrednich” opcji przyspieszenia wykonywania aplikacji:
Wieloprzetwarzanie chipów (CMP)- dwa rdzenie procesora są fizycznie umieszczone na jednej kości za pomocą wspólnej lub oddzielnej pamięci podręcznej. Oczywiście rozmiar kryształu okazuje się dość duży, a to nie może nie wpływać na koszt. Zauważ, że kilka z tych „podwójnych” procesorów może również działać w systemie wieloprocesorowym.
Wielowątkowość wycinkowa czasu... Procesor przełącza się między wątkami programu w stałych odstępach czasu. Koszty ogólne mogą być czasami imponujące, zwłaszcza jeśli proces jest w toku.
Wielowątkowość włączania zdarzeń... Przełączanie zadań, gdy występują długie przerwy, takie jak „brakujące dane w pamięci podręcznej”, których duża liczba jest typowa dla aplikacji serwerowych. W takim przypadku proces oczekujący na załadowanie danych ze stosunkowo wolnej pamięci do pamięci podręcznej zostaje zawieszony, zwalniając zasoby procesora dla innych procesów. Jednak wielowątkowość typu Switch-on-Event, podobnie jak wielowątkowość Time-Slice, nie zawsze pozwala na optymalne wykorzystanie zasobów procesora, w szczególności z powodu błędów w przewidywaniu rozgałęzień, zależności instrukcji itp.
Jednoczesne wielowątkowość... W tym przypadku wątki programu są wykonywane na jednym procesorze „jednocześnie”, to znaczy bez przełączania się między nimi. Zasoby procesora przydzielane są dynamicznie, zgodnie z zasadą „jeśli z niego nie korzystasz, daj komuś innemu”. To właśnie to podejście leży u podstaw technologii Intel Hyper-Threading, do której teraz się zwracamy.
Jak działa hiperwątkowość
Jak wiecie, obecny „paradygmat komputerowy” zakłada przetwarzanie wielowątkowe. Dotyczy to nie tylko serwerów, gdzie taka koncepcja istnieje początkowo, ale także stacji roboczych i systemów stacjonarnych. Wątki mogą odnosić się do jednej lub różnych aplikacji, ale prawie zawsze aktywnych wątków jest więcej (dla pewności wystarczy otworzyć Menedżera zadań w Windows 2000 / XP i włączyć wyświetlanie liczby wątków) . Jednocześnie konwencjonalny procesor może wykonywać jednocześnie tylko jeden z wątków i jest zmuszony do ciągłego przełączania się między nimi.
Po raz pierwszy technologia Hyper-Threading została zaimplementowana w procesorze Intel Xeon MP (Foster MP), na którym była testowana. Przypomnijmy, że Xeon MP, oficjalnie zaprezentowany na IDF Spring 2002, wykorzystuje rdzeń Willamette Pentium 4, zawiera 256 KB pamięci podręcznej L2 i 512 KB/1 MB pamięci podręcznej L3 oraz obsługuje konfiguracje 4-procesorowe. Wsparcie dla Hyper-Threading jest również obecne w procesorze dla stacji roboczych - Intel Xeon (rdzeń Prestonia, 512 KB pamięci podręcznej L2), który pojawił się na rynku nieco wcześniej niż Xeon MP. Nasi czytelnicy są już zaznajomieni z konfiguracjami dwuprocesorowymi na Intel Xeon, więc rozważymy możliwości Hyper-Threadingu przy użyciu tych procesorów jako przykład - zarówno teoretycznie, jak i praktycznie. W każdym razie „prosty” Xeon jest bardziej przyziemną i przyswajalną rzeczą niż Xeon MP w systemach 4-procesorowych…
Zasada Hyper-Threading polega na tym, że w danym momencie podczas wykonywania kodu programu wykorzystywana jest tylko część zasobów procesora. Niewykorzystane zasoby można również obciążać pracą - np. można je wykorzystać do równoległego wykonywania innej aplikacji (lub innego wątku tej samej aplikacji). W jednym fizycznym procesorze Intel Xeon powstają dwa procesory logiczne (LP - Logical Processor), które współdzielą zasoby obliczeniowe procesora. System operacyjny i aplikacje „widzą” dokładnie dwa procesory i mogą rozdzielać pracę między nie, jak w przypadku pełnoprawnego systemu dwuprocesorowego.
Jednym z celów implementacji Hyper-Threading jest umożliwienie jej działania z taką samą prędkością, jak na zwykłym procesorze, jeśli jest tylko jeden aktywny wątek. W tym celu procesor ma dwa główne tryby pracy: Single-Task (ST) i Multi-Task (MT). W trybie ST aktywny jest tylko jeden procesor logiczny, który w pełni wykorzystuje dostępne zasoby (tryby ST0 i ST1); drugi LP został zatrzymany przez komendę HALT. Kiedy pojawia się drugi wątek programu, bezczynny procesor logiczny jest aktywowany (poprzez przerwanie), a fizyczny procesor przechodzi w tryb MT. Za zatrzymanie nieużywanych LP za pomocą polecenia HALT odpowiada system operacyjny, który ostatecznie odpowiada za tak samo szybkie wykonanie jednego wątku, jak w przypadku bez Hyper-Threading.

Dla każdego z dwóch LPs przechowywany jest tak zwany stan architektury (AS), który obejmuje stan różnych typów rejestrów - ogólnego przeznaczenia, kontrolnych, APIC i usługowych. Każdy LP ma swój własny APIC (kontroler przerwań) i zestaw rejestrów, do poprawnej pracy, z którym wprowadzono koncepcję Register Alias Table (RAT), która monitoruje korespondencję między ośmioma rejestrami ogólnego przeznaczenia IA-32 i 128 fizyczne rejestry CPU (jeden RAT na każdy LP).

Podczas pracy z dwoma strumieniami obsługiwane są dwa odpowiednie zestawy wskaźników następnej instrukcji. Większość instrukcji jest pobierana z pamięci podręcznej śledzenia (TC), gdzie są przechowywane w formie zdekodowanej, a dwa aktywne LP uzyskują dostęp do TC naprzemiennie, w cyklu zegarowym. Jednocześnie, gdy tylko jeden LP jest aktywny, uzyskuje wyłączny dostęp do TC bez przeplatania się zegarem. Dostęp do pamięci Microcode ROM odbywa się w ten sam sposób. Bloki ITLB (Instruction Translation Look-Aside Buffer), które są używane w przypadku braku niezbędnych instrukcji w pamięci podręcznej instrukcji, są duplikowane i każdy dostarcza instrukcje dla własnego strumienia. Jednostka dekodująca instrukcje IA-32 Instruction Decode jest współdzielona i w przypadku konieczności dekodowania instrukcji dla obu strumieni obsługuje je po kolei (znowu w każdym cyklu zegara). Bloki kolejki Uop i alokatora są podzielone na dwie części, przydzielając połowę elementów dla każdego LP. Harmonogramy, w liczbie 5, przetwarzają kolejki dekodowanych poleceń (Uops), pomimo przynależności do LP0 / LP1 i wysyłają polecenia wykonania niezbędnych Jednostek Wykonawczych, w zależności od gotowości do wykonania pierwszego i dostępności drugiego. Pamięci podręczne wszystkich poziomów (L1 / L2 dla Xeon, a także L3 dla Xeon MP) są całkowicie współdzielone między dwoma LP, jednak aby zapewnić integralność danych, zapisy w DTLB (Data Translation Look-Aside Buffer) są wyposażone w deskryptory w forma logicznych identyfikatorów procesorów.
W ten sposób instrukcje obu procesorów logicznych mogą być wykonywane jednocześnie na zasobach jednego procesora fizycznego, które podzielone są na cztery klasy:
- zduplikowane (zduplikowane);
- w pełni udostępniony (w pełni udostępniony);
- z deskryptorami elementów (Entry Tagged);
- partycjonowana dynamicznie w zależności od trybu pracy ST0 / ST1 lub MT.
Jednocześnie większość aplikacji akcelerowanych w systemach wieloprocesorowych może być również akcelerowana na procesorze z włączoną funkcją Hyper-Threading bez żadnych modyfikacji. Ale są też problemy: na przykład, jeśli jeden proces znajduje się w pętli oczekiwania, może zająć wszystkie zasoby fizycznego procesora, uniemożliwiając działanie drugiego LP. W związku z tym wydajność podczas korzystania z funkcji Hyper-Threading może czasami spaść (nawet o 20%). Aby temu zapobiec, Intel zaleca używanie instrukcji PAUSE (wprowadzonej w IA-32 od Pentium 4) zamiast pustych pętli oczekiwania. Trwają też dość poważne prace nad automatyczną i półautomatyczną optymalizacją kodu podczas kompilacji – na przykład kompilatory serii Intel OpenMP C++ / Fortran Compilers () poczyniły w tym zakresie znaczne postępy.
Innym celem pierwszej implementacji Hyper-Threading, według Intela, było zminimalizowanie wzrostu liczby tranzystorów, powierzchni matrycy i zużycia energii przy zauważalnym wzroście wydajności. Pierwsza część tego zobowiązania została już wypełniona: dodanie obsługi Hyper-Threading do Xeon / Xeon MP zwiększyło obszar matrycy i zużycie energii o mniej niż 5%. Co się stało z drugą częścią (performance), musimy jeszcze sprawdzić.
Część praktyczna
Z oczywistych powodów nie testowaliśmy 4-procesorowych systemów serwerowych na Xeon MP z włączoną funkcją Hyper-Threading. Po pierwsze, jest to dość czasochłonne. A po drugie, jeśli zdecydujemy się na taki wyczyn – i tak teraz, niecały miesiąc po oficjalnej zapowiedzi, zdobycie tak drogiego sprzętu jest absolutnie nierealne. Dlatego postanowiono ograniczyć się do tego samego układu z dwoma procesorami Intel Xeon 2,2 GHz, na których przeprowadzono pierwsze testy tych procesorów (patrz link na początku artykułu). System został oparty na płycie głównej Supermicro P4DC6 + (chipset Intel i860), zawierał 512 MB pamięci RDRAM, kartę graficzną opartą na układzie GeForce3 (64 MB DDR, sterowniki Detonator 21.85), dysk twardy Western Digital WD300BB oraz 6X DVD- ROM; Windows 2000 Professional SP2 był używany jako system operacyjny.
Najpierw kilka ogólnych wrażeń. Podczas instalacji jednego Xeona z jądrem Prestonia, na starcie systemu BIOS wyświetla komunikat o obecności dwóch procesorów; jeśli zainstalowane są dwa procesory, użytkownik widzi komunikat o czterech procesorach. System operacyjny zwykle rozpoznaje „oba procesory”, ale tylko wtedy, gdy spełnione są dwa warunki.
Po pierwsze, w konfiguracji CMOS najnowszych wersji BIOS płyt Supermicro P4DCxx pojawił się element Enable Hyper-Threading, bez którego system operacyjny rozpoznaje tylko fizyczny procesor. Po drugie, możliwości ACPI są używane do informowania systemu operacyjnego o obecności dodatkowych procesorów logicznych. Dlatego, aby włączyć Hyper-Threading, opcja ACPI musi być włączona w konfiguracji CMOS, a warstwa HAL (Hardware Abstraction Layer) z obsługą ACPI musi być również zainstalowana dla samego systemu operacyjnego. Na szczęście w systemie Windows 2000 zmiana warstwy HAL ze standardowego PC (lub MPS Uni-/Multiprocessor PC) na ACPI Uni-/Multiprocessor PC jest łatwa – poprzez zastąpienie „sterownika komputera” w menedżerze urządzeń. Jednocześnie w przypadku Windows XP jedynym legalnym sposobem migracji do ACPI HAL jest ponowna instalacja systemu na istniejącej instalacji.
Ale teraz wszystkie przygotowania zostały poczynione, a nasz Windows 2000 Pro już mocno wierzy, że działa w systemie dwuprocesorowym (choć w rzeczywistości jest zainstalowany tylko jeden procesor). Teraz tradycyjnie nadszedł czas, aby zdecydować o celach testowania. Więc chcemy:
- Oceń wpływ technologii Hyper-Threading na wydajność aplikacji różnych klas.
- Porównaj ten efekt z efektem instalacji drugiego procesora.
- Sprawdź, jak „sprawiedliwe” zasoby są przydzielane aktywnemu procesorowi logicznemu, gdy drugi LP jest bezczynny.
Aby ocenić wydajność, wzięliśmy zestaw aplikacji już znanych naszym czytelnikom i wykorzystywanych w testowaniu systemów stacji roboczych. Zacznijmy od końca i sprawdźmy „sprawiedliwość” procesorów logicznych. Wszystko jest niezwykle proste: najpierw uruchamiamy testy na jednym procesorze z wyłączoną funkcją Hyper-Threading, a następnie powtarzamy proces, włączając Hyper-Threading i używając tylko jednego z dwóch logicznych procesorów (za pomocą Menedżera zadań). Ponieważ w tym przypadku interesują nas tylko wartości względne, wyniki wszystkich testów są sprowadzane do „większe tym lepsze” i znormalizowane (wskaźniki systemu jednoprocesorowego bez Hyper-Threading są traktowane jako jednostka).
Cóż, jak widać, obietnice Intela zostały tutaj spełnione: przy tylko jednym aktywnym wątku wydajność każdego z dwóch LP jest dokładnie równa szybkości fizycznego procesora bez Hyper-Threading. Nieaktywny LP (zarówno LP0, jak i LP1) jest faktycznie zawieszony, a współdzielone zasoby, o ile możemy sądzić na podstawie uzyskanych wyników, są całkowicie przeniesione na korzystanie z aktywnego LP.

Dlatego wyciągamy pierwszy wniosek: dwa procesory logiczne są w rzeczywistości równe, a włączenie funkcji Hyper-Threading nie „zakłóca” pracy jednego wątku (co samo w sobie nie jest złe). Teraz zobaczmy czy to włączenie "pomaga", a jeśli tak to gdzie i jak?
Wykonanie... Wyniki czterech testów w pakietach do modelowania 3D 3D Studio MAX 4.26, Lightwave 7b i A|W Maya 4.0.1 ze względu na podobieństwo są połączone w jeden diagram.

We wszystkich czterech przypadkach (dla Lightwave - dwie różne sceny) obciążenie procesora z jednym procesorem z wyłączoną funkcją Hyper-Threading jest prawie zawsze utrzymywane na poziomie 100%. Niemniej jednak, gdy Hyper-Threading jest włączony, obliczanie sceny jest przyspieszone (w wyniku czego nawet żartowaliśmy o obciążeniu procesora powyżej 100%). W trzech testach widzimy 14-18% wzrost wydajności z Hyper-Threadingu - z jednej strony niewiele w porównaniu do drugiego procesora, ale z drugiej całkiem niezły, biorąc pod uwagę efekt "darmowego" tego efektu. W jednym z dwóch testów z Lightwave zysk wydajności jest praktycznie zerowy (podobno wynika to ze specyfiki tej aplikacji, która jest pełna dziwności). Ale nigdzie nie ma negatywnego wyniku, a zauważalny wzrost w pozostałych trzech przypadkach jest zachęcający. I to pomimo tego, że równoległe procesy renderowania wykonują podobną pracę i najprawdopodobniej nie są najlepszym sposobem na jednoczesne wykorzystanie zasobów fizycznego procesora.
Kodowanie Photoshop i MP3... Kodek GOGO-no-coda 2.39c jest jednym z nielicznych obsługujących SMP i wykazuje 34% wzrost wydajności dzięki technologii dwuprocesorowej. Jednocześnie efekt Hyper-Threadingu w tym przypadku jest zerowy (nie uważamy, że różnica 3% jest znacząca). Ale w teście z Photoshopem 6.0.1 (skrypt składający się z dużego zestawu poleceń i filtrów) widać spowolnienie, gdy włączona jest funkcja Hyper-Threading, chociaż drugi fizyczny procesor dodaje w tym przypadku 12% wydajności. To właściwie pierwszy przypadek, w którym Hyper-Threading powoduje spadek wydajności…

Profesjonalny OpenGL... Od dawna wiadomo, że SPEC ViewPerf i wiele innych aplikacji OpenGL często spowalnia na systemach SMP.
OpenGL i podwójny procesor: dlaczego nie są przyjaciółmi
Wielokrotnie w naszych artykułach zwracaliśmy uwagę czytelników na to, że platformy dwuprocesorowe, wykonując profesjonalne testy OpenGL, bardzo rzadko wykazują znaczącą przewagę nad jednoprocesorowymi. Co więcej, często zdarzają się przypadki, gdy instalacja drugiego procesora, wręcz przeciwnie, obniża wydajność systemu podczas renderowania dynamicznych scen trójwymiarowych.
Oczywiście nie tylko my zauważyliśmy tę dziwność. Niektórzy testerzy po prostu po cichu ominęli ten fakt – na przykład cytując wyniki testu SPEC ViewPerf tylko dla konfiguracji dwuprocesorowych, unikając w ten sposób wyjaśnienia „dlaczego system dwuprocesorowy jest wolniejszy?” Inni poczynili wszelkie możliwe fantastyczne założenia dotyczące spójności skrzynek, potrzeby ich utrzymania, wynikających z tego kosztów ogólnych itp. I z jakiegoś powodu nikogo nie dziwiło, że na przykład procesory niecierpliwie się monitorowały koherencję procesorów właśnie podczas renderowania w oknie OpenGL (pod względem „obliczeniowej” istoty nie różni się on zbytnio od innych problemów obliczeniowych) .
W rzeczywistości wyjaśnienie, naszym zdaniem, jest znacznie prostsze. Jak wiesz, aplikacja może działać na dwóch procesorach szybciej niż na jednym, jeśli:
- w tym samym czasie działają więcej niż dwa lub więcej wątków;
- wątki te nie przeszkadzają sobie nawzajem w wykonywaniu — na przykład nie konkurują o udostępniony zasób, taki jak zewnętrzne urządzenie pamięci masowej lub interfejs sieciowy.
Przyjrzyjmy się teraz w uproszczeniu, jak wygląda renderowanie OpenGL wykonywane przez dwa wątki. Jeśli aplikacja "widząc" dwa procesory tworzy dwa wątki renderowania OpenGL, to dla każdego z nich, zgodnie z regułami OpenGL, tworzony jest własny kontekst gl. W związku z tym każdy wątek renderuje się we własnym kontekście gl. Problem polega jednak na tym, że dla okna, w którym wyświetlany jest obraz, tylko jeden kontekst gl może być jednocześnie aktualny. W związku z tym wątki w tym przypadku po prostu „z kolei” wyprowadzają wygenerowany obraz do okna, naprzemiennie czyniąc ich kontekst bieżącym. Nie trzeba dodawać, że ta „zmiana kontekstów” może być bardzo kosztowna pod względem kosztów ogólnych?
Podamy też np. wykresy wykorzystania dwóch procesorów w kilku aplikacjach wyświetlających sceny OpenGL. Wszystkie pomiary zostały wykonane na platformie o następującej konfiguracji:
- jeden lub dwa procesory Intel Xeon 2,2 GHz (Hyper-Threading wyłączone);
- 512 MB pamięci RDRAM;
- Supermicro P4DC6 + płyta główna;
- Karta graficzna ASUS V8200 Deluxe (NVidia GeForce3, 64 MB DDR SDRAM, sterowniki Detonator 21.85);
- Windows 2000 Professional SP2
- tryb wideo 1280x1024x32 bpp, 85 Hz, synchronizacja pionowa wyłączona.
Niebieski i czerwony przedstawiają wykresy wykorzystania odpowiednio CPU 0 i CPU 1. Środkowa linia to końcowy wykres wykorzystania procesora. Trzy wykresy odpowiadają dwóm scenom z 3D Studio MAX 4.26 i części testu SPEC ViewPerf (AWadvs-04).
Użycie procesora: Animacja 3D Studio MAX 4.26 - Anibal (z manipulatorami) .max
Użycie procesora: Animacja 3D Studio MAX 4.26 - Rabbit.max
Wykorzystanie procesora: SPEC ViewPerf 6.1.2 - AAdvs-04Ten sam wzorzec powtarza się w wielu innych aplikacjach korzystających z OpenGL. Dwa procesory w ogóle nie przeszkadzają w pracy, a łączne wykorzystanie procesora okazuje się na poziomie 50-60%. Jednocześnie, w przypadku systemu jednoprocesorowego, we wszystkich tych przypadkach użycie procesora jest pewnie utrzymywane na poziomie 100%.
Dlatego nie jest zaskakujące, że tak wiele aplikacji OpenGL nie przyspiesza zbytnio na podwójnych systemach. Cóż, fakt, że czasami nawet zwalniają, ma naszym zdaniem całkowicie logiczne wytłumaczenie.



Można powiedzieć, że przy dwóch procesorach logicznych spadek wydajności jest jeszcze bardziej znaczący, co jest całkiem zrozumiałe: dwa procesory logiczne zakłócają się nawzajem w taki sam sposób, jak dwa fizyczne. Ale ich ogólna wydajność oczywiście okazuje się niższa, więc po włączeniu Hyper-Threading spada nawet bardziej niż w przypadku działania dwóch fizycznych procesorów. Wynik jest przewidywalny, a wniosek prosty: Hyper-Threading, podobnie jak „prawdziwy” SMP, jest czasami przeciwwskazany dla OpenGL.

Aplikacje CAD... Poprzedni wniosek potwierdzają wyniki dwóch testów CAD - SPECapc dla SolidEdge V10 i SPECapc dla SolidWorks. Wydajność graficzna tych testów dla Hyper-Threading jest podobna (choć w przypadku systemu SMP dla SolidEdge V10 wynik jest nieco wyższy). Ale wyniki testów CPU_Score ładujących procesor dają do myślenia: 5-10% zysku z SMP i 14-19% spowolnienia z Hyper-Threadingu.


Ale ostatecznie Intel uczciwie przyznaje w niektórych przypadkach możliwość spadku wydajności podczas Hyper-Threading - na przykład podczas korzystania z pustych pętli oczekiwania. Możemy jedynie założyć, że jest to powód (szczegółowe badanie kodu SolidEdge i SolidWorks wykracza poza zakres tego artykułu). W końcu wszyscy znają konserwatyzm programistów CAD, którzy preferują sprawdzoną niezawodność i nie spieszą się specjalnie z przepisywaniem kodu z uwzględnieniem nowych trendów w programowaniu.
Podsumowując, czyli „Uwaga, właściwe pytanie”
Hyper-Threading działa, nie ma co do tego wątpliwości. Oczywiście technologia nie jest uniwersalna: istnieją aplikacje, które są „gorsze” od Hyper-Threadingu i jeśli ta technologia się rozprzestrzeni, pożądane byłoby ich zmodyfikowanie. Ale czy to samo nie wydarzyło się w odpowiednim czasie z MMX i SSE i nadal dzieje się z SSE2?
Rodzi to jednak pytanie o możliwość zastosowania tej technologii w naszych realiach. Od razu odrzucimy wariant systemu jednoprocesorowego opartego na Xeonie z Hyper-Threadingiem (lub niech będzie tylko tymczasowy, do czasu zakupu drugiego procesora): nawet 30% wzrost wydajności nie uzasadnia ceny w w każdym razie - lepiej kupić zwykłego Pentium 4. Liczba procesorów pozostaje od dwóch lub więcej.
Teraz wyobraźmy sobie, że kupujemy dwuprocesorowy system Xeon (powiedzmy, z Windows 2000/XP Professional). Zainstalowane są dwa procesory, włączony Hyper-Threading, BIOS wyszukuje aż cztery procesory logiczne, teraz jak możemy wystartować... Stop. Ale ile procesorów zobaczy nasz system operacyjny? Zgadza się, dwa. Tylko dwa, ponieważ po prostu nie jest przeznaczony dla większej liczby. Będą to dwa fizyczne procesory, czyli wszystko będzie działać dokładnie tak samo, jak przy wyłączonym Hyper-Threadingu - nie wolniej (dwa "dodatkowe" logiczne procesory po prostu się zatrzymają), ale nie szybciej (zweryfikowane dodatkowymi testami, wyniki nie są są podane ze względu na ich kompletne dowody). Hmmm, trochę przyjemne...
Co zostało? Cóż, naprawdę nie umieszczaj Advanced Server lub .NET Server na naszej stacji roboczej? Nie, system zainstaluje się sam, rozpozna wszystkie cztery procesory logiczne i będzie działał. Ale system operacyjny serwera wygląda trochę dziwnie na stacji roboczej, delikatnie mówiąc (nie wspominając o aspektach finansowych). Jedyny rozsądny przypadek to taki, w którym nasz dwuprocesorowy system Xeon będzie działał jako serwer (przynajmniej niektórzy kolekcjonerzy bez wahania rozpoczęli produkcję serwerów na stacjach roboczych-procesorach Xeon). Jednak w przypadku dwóch stacji roboczych z odpowiednimi systemami operacyjnymi zastosowanie technologii Hyper-Threading pozostaje wątpliwe. Firma Intel aktywnie opowiada się teraz za licencjonowaniem systemu operacyjnego w oparciu o liczbę nie logicznych, ale fizycznych procesorów. Dyskusje wciąż trwają i generalnie wiele zależy od tego, czy zobaczymy system operacyjny dla stacji roboczych z obsługą czterech procesorów.
Cóż, z serwerami wszystko wychodzi całkiem prosto. Na przykład Windows 2000 Advanced Server, zainstalowany na dwuprocesorowym systemie Xeon z włączoną funkcją Hyper-Threading, „zobaczy” cztery procesory logiczne i będzie na nich płynnie działać. Aby ocenić korzyści płynące z Hyper-Threading w systemach serwerowych, przedstawiamy wyniki Intel Microprocessor Software Labs dla dwuprocesorowych systemów Xeon MP i kilku aplikacji serwerowych Microsoft.

20-30% wzrost wydajności dla dwuprocesorowego serwera „za darmo” jest więcej niż kuszące (szczególnie w porównaniu z zakupem „prawdziwego” systemu czteroprocesorowego).
Okazuje się więc, że w tej chwili praktyczne zastosowanie Hyper-Threadingu jest możliwe tylko na serwerach. Problem ze stacjami roboczymi zależy od rozwiązania licencjonowania systemu operacyjnego. Jednak jeszcze jedno zastosowanie Hyper-Threadingu jest całkiem realistyczne - jeśli procesory desktopowe również otrzymają wsparcie dla tej technologii. Na przykład (pomyślmy sobie), dlaczego jest zainstalowany system z procesorem Pentium 4 z obsługą Hyper-Threading i Windows 2000/XP Professional z obsługą SMP - od serwerów po systemy stacjonarne i mobilne.